我们看一些数据库索引文章的时候,避免不了会看到B-Tree或者B+Tree,那么什么是B-Tree呢?为什么数据库普遍喜欢这个数据结构呢?下面就从这两点说起
什么是B-Tree
B树最早接触时在严蔚敏的数据结构中了解到的,那么我们根据一张图来看看她给出的定义
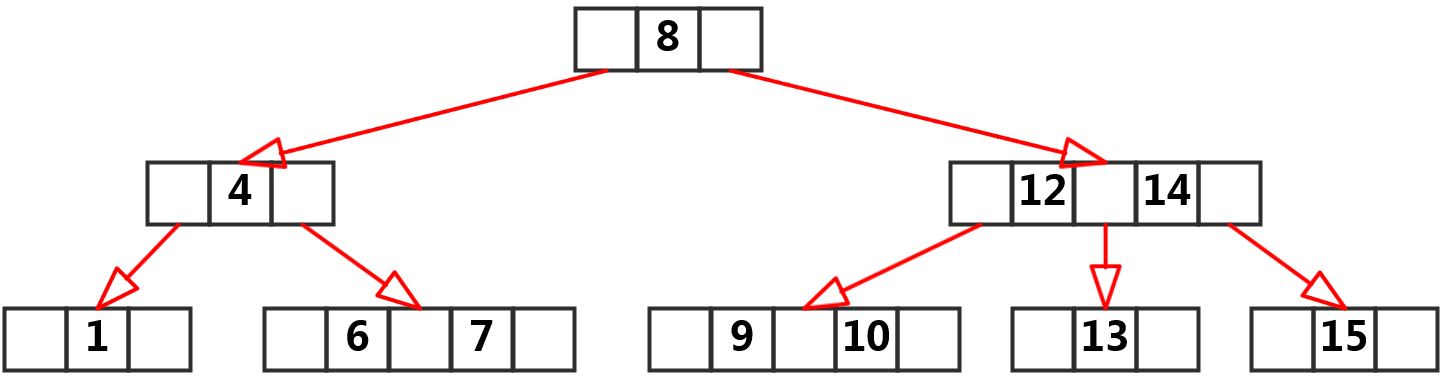

从特性中我们看到:
- B树是一个多叉树,而且是平衡树,关键字存放在整颗树中,性能等价于二分查找。
- 因为每个节点至少有M/2个儿子,所以可以保证树的深度不会过深,但是新增节点和删除节点也要保证这个特性,所以会出现节点的分裂与合并。
接下来我们聊聊B+树
其实B+树的出现正是应文件系统所需才出现的一种数据结构,他是B树的变种,他的定义和B树有区别也有联系:
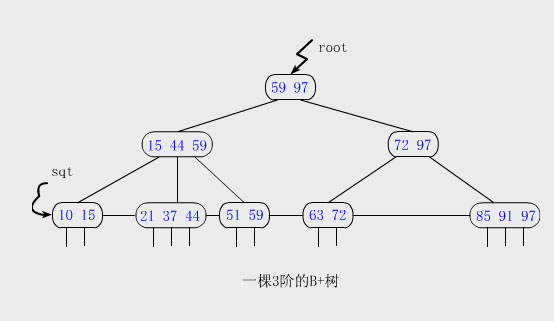
- 有n颗子树的节点中含有n个关键字;
- 所有叶子节点中包含了全部关键字信息,及指向含有这些关键字记录的指针,且叶子节点本身依关键字的大小从小到大顺序连接;
- 所有的非终端节点可看成是索引部分,节点中仅含有其子树(根节点)中的最大或最小关键字;
数据库为什么要用B树
其实数据库不用索引也是可以的,但是索引是为了加快查询,这在OLADP(线上分析处理)的时候是很重要的。而索引其实就是一种数据结构,有hash索引,全文索引,B+Tree索引,其实就是不同的数据结构,我们现在只谈论为什么用BTree。在之前我们先学习两个东西:
- 局部性原理:当一个数据被用到时,其附近的数据通常也会马上被用到
- 磁盘预读:即使使用了磁盘页中的一部分数据,磁盘也会把整个页读取给内存
随着内存越来越大,很多时候我们都会做缓存,其实预读也是缓存。由于内存和磁盘的IO速度根本不在一个量级,在加上局部性原理,我们一般会按页读取(通常一页为4K)。数据库设计者把索引的每个节点都设计成一页,而且出度设置很大,这样就减少了深度,建设深度为d,那么一次查询最多进行d-1次IO就行了。

